Preface
This blog post is part of the “maths as a note-taking foundation” series, which can be found here.
The focus of this post is to introduce a concept called link integrity - an idea that exists in various forms throughout many different note taking applications, but this time visualized and implemented rigorously through type theory.
This post heavily references the Norg file format. Some prior knowledge of it is expected!
Why?

Before you solve any problem, it’s always good to fully understand said problem and whether it’s even the right problem in the first place. Let’s start off by discussing links within Norg and how they work.
A Web of Cobwebs
Links in Norg follow a very simple structure:
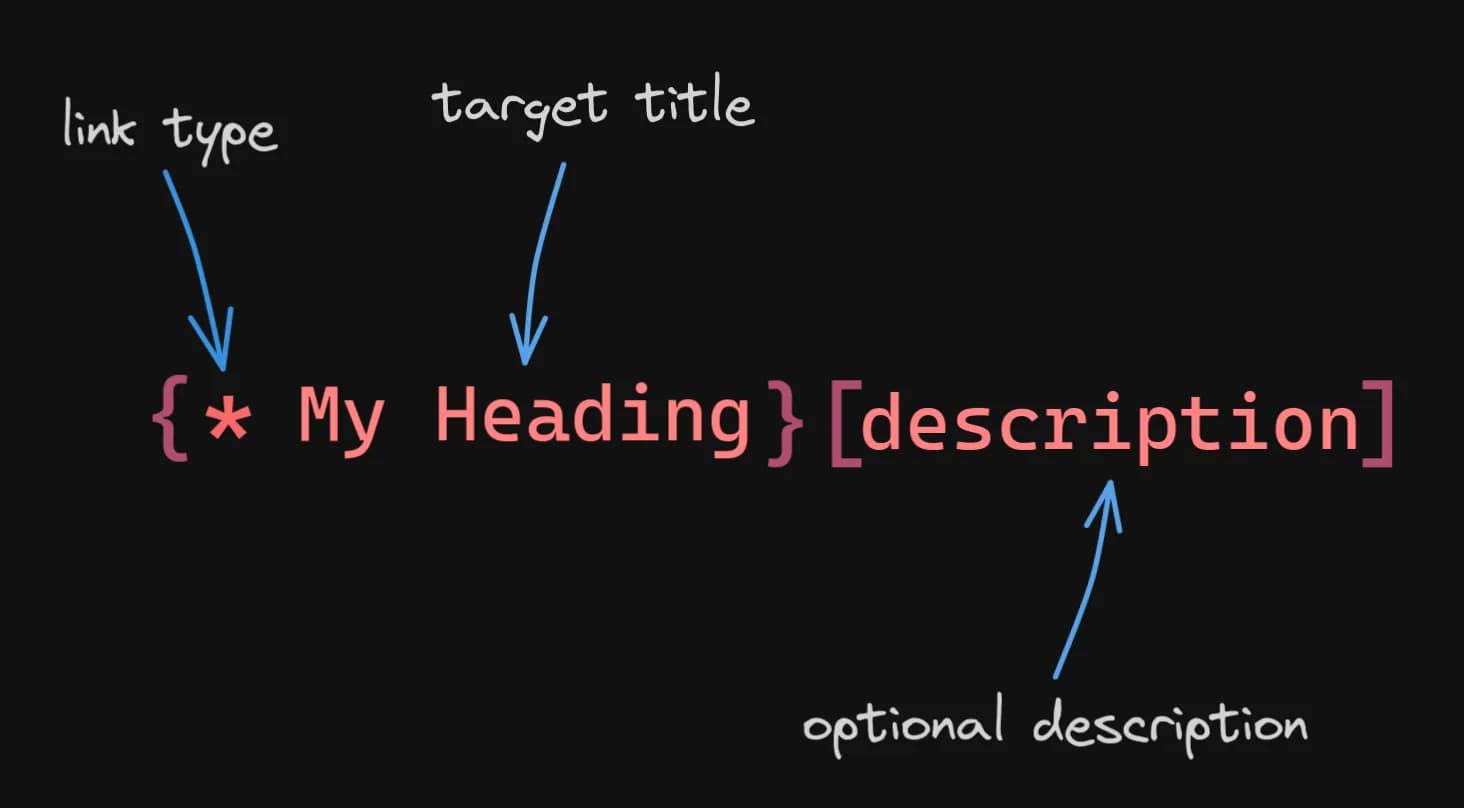
Something to note is that in Norg links can have a type, that is, you can be as general or as specific about the target of your link as you’d like.
Want to specifically link to a level 2 heading?
{** Title} is your best friend. Want to link to any object without constraints? {# Title} is
there to help (the # being borrowed from markdown’s syntax for “anything with a given ID”).
Naturally, this makes the process of resolving the target of a link more complex than in, say, Markdown. In Markdown you have one type of link which just links to anything, so you can run a generic search over the document and try to locate the target. Here, however, you have to start understanding different parts of the document and their types so that you can route the user to the appropriate location whenever trying to resolve the link.
This ability to be as specific as you like is great, although an interesting
question starts arising once you start considering conflicts… oh yeah, about
those. What if we have two headings with the same name? What if there are two
items of different types but with the same title? How does {# Title} know
where to link to?
Most note taking applications simply choose the element that is higher up in the document. Consider the following example:
* Title
^ Title
This is a footnote with a title!
I would like to link to {# title} here.
Since there are two objects with a title of “Title”, the link resolver will just choose the first thing it sees, in this case it will be the heading. Let’s think about this for a moment - in an isolated case, this seems very reasonable. It would be stupid to issue an error here! The link resolver can infer what we’re talking about, so why trouble the user when we can think for them instead?
This sort of thought process, though, only works for the isolated case. Let’s flip the question around, let’s assume you have a knowledge base of 10 thousand notes (each an individual file). It’s very safe to assume many of these files will be interconnected through links. Now there’s an issue - a general link resolver will choose the first thing it sees whenever there’s a conflict, but what if that’s not the target the user intended to link to? Or, worse, what if the link worked when the user initially made the note, but now that they have built out and refactored many of their files over the course of several years it points elsewhere?
The core of the issue is quite obvious here, links do not bind themselves to their targets. If the target is ever removed or changed all of your notes are, to put it bluntly, screwed.
Thus, if we want to solve the issue, we need to ensure that, every time a target of a link is altered in some way, all links within the whole knowledge base of a user get updated too, to reflect the change. The idea is pretty neat!
Existing Solutions
But wait, this literally already exists mate. Just look at Obsidian which updates links whenever you rename a file. So much for “link integrity”.
- You (probably)
Here’s the key point - other implementations usually have some predetermined criteria (file rename, heading rename) by which they update their links to match their new targets. Generalizing this behaviour to every possible target type (files, headings, footnotes, definitions, paragraphs) sounds like a lot of work though, perhaps even impossible.
So, is it possible…?
Link Integrity
Henceforth I would like to change the way you perceive links within Norg. Let’s approach the problem the “Rust” way - rigorously, with slight upfront mental overhead, but with large scale and long term benefits. Let’s call it link integrity.
Here are the rules we are laying out for ourselves:
- When a user creates a link, that link “binds” itself to its target.
- Whenever the target is modified, all links pointing to that target also update accordingly.
- Changing a link will not update the target (too chaotic, besides, we are interested in link integrity, not target integrity).
- The user can sleep knowing that no matter how they mess around with their documents their links will continue to point to a valid location (provided they don’t completely delete the link target).
- Errors can and will be issued whenever a link conflict is found (this comes at a slight initial inconvenience but with a massive long-term benefit).
This idea is quite beautiful when you consider it — all of your links will update in realtime as you make various refactors to parts of your document. If there are ambiguities, these ambiguities can usually be resolved by e.g. a type checker automatically without any user intervention required.
Type Theory
This whole problem very much resembles your average type theory problem. You have a bunch of links and locations those links point to, and you want to infer how these different types of data interact with each other and what rules govern them.
Type theory is known for some scary notation, but it’s not scary whatsoever! Let’s break down some super simple rules that I made specifically for Norg.
These rules define how links and targets should behave and interact with each other, and from these rules we can infer a tonne of interesting bits of information.
At its core, we need some way to represent the type of the link as well as the title of the target. We can do this fairly easily using the following two rules:
and
Woah woah woah there. If you’ve never seen this before, you’re very likely scratching your head.
The Basics
Every rule in a type system is formed of a premise and a judgement. It’s quite literally an if statement from programming languages:
So, let’s begin with the premise of our first rule: . Put simply, what we’re saying is: “if there’s a set whose every element is a character (from a to z) then…”1. Our is just some hypothetical function that returns true whenever is a valid character. Okay, so the first premise just checks if some random set in the Norg document happens to be a set of characters. What’s this judgement all about, then?:
Let’s focus on the part. What we’re saying here is “you know that
variable you defined earlier? That’s of type text”.
The funny symbol is called “gamma” (specifically capital gamma). It’s a letter from the Greek alphabet which is commonly used to denote a context. A context is just a long list of things and their associated types. These “things” are variables that we figured out beforehand.
Take this document as an example:
Paragraph 1.
Paragraph 2.
As we’re parsing through the document, we first encounter paragraph 1. At this
point, our context is completely empty. But, through the first rule
that we explained and defined earlier, the type checker will recognize that
“Paragraph 1” is, well, text, and it will add it to its context.
Then, as we’re parsing paragraph 2, the context now contains:
The gamma variable is basically just storage for all of the things we know as we’re parsing through the document! This fact will really help us later :p.
The symbol literally means “it follows that”. So, to sum up the entire
rule in a simple sentence: “if some set is a sequence of characters then
from our context it follows that its type is text”. Or, to put it even more
simply: “if you find some characters bunched together, put it in to gamma and give it a type text”.
So, now that you’re able to understand the first rule for paragraphs, let’s see if you can figure out the second rule. I recommend you pause and ponder for a while, see if you can intuitively make sense of what’s happening. Know that means the cardinality of a set, i.e. its number of elements.
Heading Rule
Let’s take a close look at the rule one last time:
Let’s break it down, remember, the top is the premise, the bottom is the judgement.
If there’s some set of values where each value within that set belongs to a
set of ’*‘s, then the judgement holds. Wait, that sounds weird. What we’re
quite literally matching here is if all elements of the set are an
asterisk! That honestly makes sense, given the start of a heading can only be
built up of consecutive asterisks: *** My Heading.
Now, for the judgement. We’re saying that from it follows that that very set of asterisks
bundled next to each other is of type . What does that mean? Our Heading in
this case is a polytype, an overly fancy term for a type which can hold extra data (e.g. other types).
The simplest type is the monotype.
Because headings can have many levels, we would like to differentiate between each level, so instead
of calling everything a Heading we also include the level of the heading we’re dealing with within
the type itself! Remember that means “the amount of items has”. So, if we have
4 consecutive asterisks, that means the resulting type is a Heading 4, i.e. a level 4 heading!
The Rest of the Basics
That was a doozy! Feel free to take a break or something to process all of that information. There’s still lots to go, though, so be warned!
Let’s go through the rest of the rules in our “link type system” by enumerating each rule!
-
Object rule: An expression succeeded by text forms an object.
-
Link integrity rule: A link pointing to a given object must have the same type.
-
Link generalization rule: If a typed link is pointing to a uniquely named object it may be generalized to a generic link.
I feel your pain, let’s go over every rule one by one.
These aren’t all of the rules in our type system, there are some missing bits here and there. However, these are all that are needed to prove the point of this blog post:
-
The first rule states that if you have an expression (
***) and some text (Title) they can both be combined when side by side (*** Title) into anObjecttype.If two or more rules are put side by side in the top half, that means all must be true for the bottom statement to hold true (think of it as an
andstatement from programming).This type is handy as it implicitly states that its second component must be of type
text- it saves us some typing in the other rules! Instead of having to always specify that type is of typetext, this is now implied wherever we useObjectinstead. -
The link integrity rule states that if there is some object with type then a link to that object must be a link to an object of that same type (). Simply put, if you have a heading and you link to it, that means that the type of the link itself is a link to a heading… makes sense.
-
The last rule is for general links specifically. Here the notation gets a little dense.
So, what are we saying here? First, we’re asserting that there is some link to an object of type . We don’t know what is, we just know it’s some type. If such a link exists, we can then move on to the second assertion. The second assertion checks if there isn’t a different link of a different type with the same title.
To illustrate, imagine two links,
{* title}and{** title}. Both links have two distinct types, but both have the same title. If we were to generalize this link to{# title}, the type system wouldn’t be able to guess which of thosetitles we actually meant. That’s why the second check exists in this rule. It makes sure that we have some link and that link is uniquely bound to one specific title.If both of those rules hold true, we can now say that there is some general link with the exact same title and that it’s equivalent to the more specific title.
To illustrate this even further, if you have a document:
* Title This is a link to {* Title}!With this rule we can say that no matter if you had typed
{# Title}or{* Title}, the outcome would have been the exact same.What you see in the type definition () is the same thing as saying “for all possible values of alpha”. Yet again, this is just more fancy notation for “this is a general link to some title which can theoretically point to anything”. You’ll see why this rule is particularly interesting later.
Using our Type Notation
I have laid out all of these rules to now reach the climax of this entire post. If you’re still here, you’re one brave soldier. I laid out all of these rules to specifically talk about the link generalization rule, as that’s where all of the meat of the discussion stands, and I think it best illustrates how the link integrity system will function.
Suppose that I have the following basic document:
* Homework
** Plants
Remember to do your homework about {# plants}.
Let’s assume I wrote this document 2 months ago, without a care in the world for anything. Now, I make a change to that very file, but I forget that doing so would break the link:
* Plants
I really wanted to talk about plants in this heading.
* Homework
** Plants
Remember to do your homework about {# plants}.
Oh no, our document is broken! Now the link would point to the top heading… ruining it all. But wait, our link integrity system is actively running in the background!
Let’s rewind to before the change. When we created the {# plants} link, our type system
managed to do something special. It was able to infer the type of the generic link, thanks
to the link generalization rule. Remember, our link generalization rule states that for some
{# plants} link to exist it must point to a unique title - and indeed, in the snippet before
the change, {# plants} has only one possible target: ** Plants. That means the type system
inferred that the general link, at its core, points to the level 2 heading.
Now, after the change, there are two possible targets, so the general link rule cannot be
satisfied. But, we already inferred beforehand that the general link used to point to ** Plants,
so we can exploit that!
After the change was made, the link integrity algorithm grinds its gears, and the link gets
converted into {** plants}! We knew the type of the general link is actually Link Object Heading 2,
and we also knew that the new change introduces a conflict in our type system, so using that information
we were able to fix the error by ensuring that the link continues to point to the correct location by
making the link more specific, even after we “broke” our document!
I don’t know about you, to me this is just amazing. However, let’s assume a different case, as order matters in a type system.
The Error Case
Now let’s invert the order of the previous example, let’s say we start off with the following document:
* Plants
I really wanted to talk about plants in this heading.
* Homework
** Plants
Remember to do your homework!
And our user now adds a general link to plants:
* Plants
I really wanted to talk about plants in this heading.
* Homework
** Plants
Remember to do your homework about {# plants}.
At this point, there was no prior inference that could have helped us in fixing the type error. That means that in this case, the user will see an error stating that the link is ill-formed and ambiguous, and will see a set of tooltips to fix the error.
The good news is - this case is actually very rare. It’s much more common that the type system will have already inferred something as the user is making changes rather than the type system having no prior context to begin with.
The Most Common Case
The most common case will be the renaming of either (but not both):
- The type of a target
- The title of a target
Changing the Target’s Type
If we have a level 1 heading (* Title) and a link to that heading ({* Title})
and the type gets updated to *** Title then the link will follow: {*** Title}.
This can be done because the title remains the same. This gives the type system enough context to be able to solve an equation with one variable (the new type of the heading).
After solving that case, all links can be updated accordingly.
Changing the Target’s Title
If we have a level 1 heading (* Title) and a link to that heading ({* Title})
but the title gets updated to * Some other title then the link will follow: {* Some other title}.
This can be done because, yet again, only one variable has changed, and the type system can use type inference to figure out the changed value (with some added help from the editor running Norg).
Changing the Target’s Title and Type
In the case where both the type and the title are updated, the type system is not able to infer the new target of the link. Changing both the type and title of a target is equivalent to completely deleting the old target and creating a new, unrelated target from scratch.
As we know, when a link is pointing to a target that doesn’t exist, it will issue an error. This is by design. Users will receive a useful error message when a change they made to their notes negatively impacts links that point to that specific note.
Going Forward
Hope this post sparked at least a bit of curiosity and excitement in you (and not just pure confusion)!
The irony of everything is that, despite this blog post being long as hell, we’ve only scratched
the surface. In Norg, links can bind to files, but they can also have scopes ({* Heading : ** Heading 2} searches
for a level-2 heading within a level-1 heading with a given name).
The amazing thing is is that, if we extend our type system accordingly, all of the rules that I have laid out will still stand and will pave way to even more complex but consistent behaviour in our link integrity system.
This means that even in the most complex cases the type checker will always be smart and will have some incredible type inference and, no matter how we refactor our files, all of our links will remain intact. I hope this conceptual introduction caught your attention! Link integrity will be a real system that I hope to implement in Neorg one day, here I am laying out the theoretical foundations for it. See you on the flipside!
Footnotes
-
To all pedantic mathematicians out there, what this actually means is “if there’s a set whose elements belong to the set of all possible characters”. No need to complicate things as much though. ↩